SEP Tachometer - the Best Way to Save Money!
Analyze your Savings with the SEP sesam Si3 Deduplication Technology
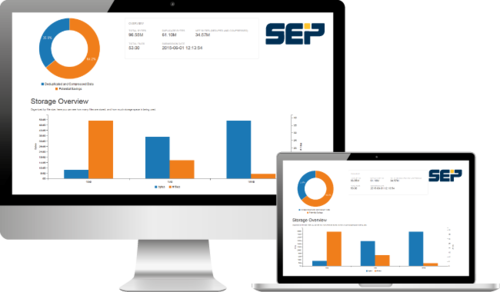
With SEP Tachometer we provide you a flexible data analysis tool which enables you to analysis your data easily, fast and for free.
- Install SEP Tachometer on your Windows, Linux or Mac machine.
- Thanks to SEP Tachometer, you'll be able to analyze your local SEP sesam DataStore or any other mounted storage (even NFS shares).
- SEP Tachometer analyzes the structure of your data and calculates potential savings using SEP sesam Si3 deduplication.
- Results are provided in a comprehensible graphical layout, allowing you to gain a fast and easy overview of your potential data savings.
- Potential backup storage saving
- Total count of analyzed files
- File size ranking
- Statistical evaluation of file extensions
- Statistical evaluation of file sizes by extension